Set colours to differentiate between servers/environments
You can set SSMS connection properties to give a visual indication of which server your queries are connected to.
When you connect to a SQL Server instance, click on the ‘Options’ button:
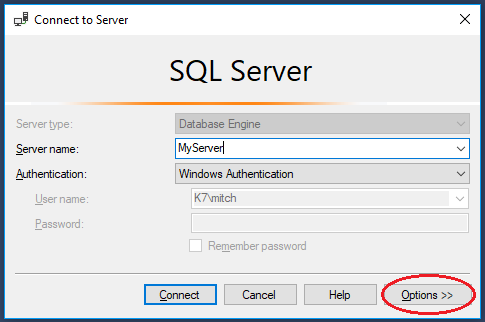
Then click on the ‘Connection Properties’ tab and choose a custom colour for your connection:
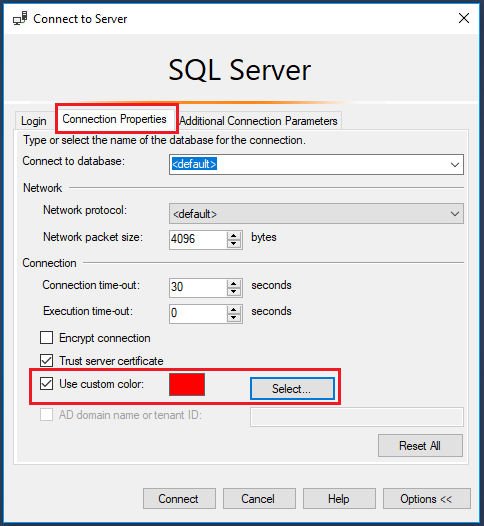
Suggested colours for your environments:
- Production – Red
- UAT – Orange
- QA – Yellow
- Dev – Blue
- Local – Green
Once set, every time you open a connection to a server, it will display the assigned colour in the SSMS status bar.
Configure SSMS tabs to only show file names
Follow Brent Ozar’s simple instructions here: SSMS 2016: It Just Runs More Awesomely (It’s not just for SSMS 2016). This makes tabs easier to read and pinning tabs is a great idea for often used scripts. [I also like to set my status bar position to the top of the query window]:
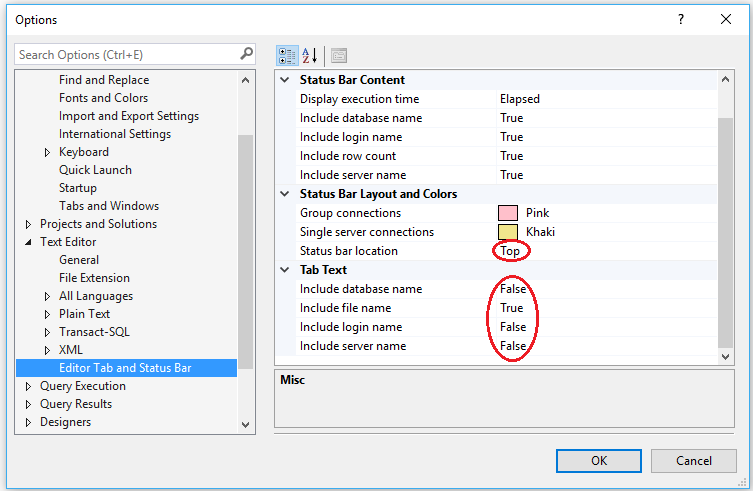
While you are in the Options dialog, go to Tools -> Options -> Environment -> AutoRecover and make sure AutoRecover files is turned on, with appropriate values set.
Cycle through clipboard text
All Windows users will be familiar with the shortcut keys CTRL+C and CTRL+V. The ‘Cycle Clipboard Ring’ feature in SSMS keeps track of last 20 items you have cut/copied. You can use CTRL+SHIFT+V to paste the last copied item from the clipboard just as you would with CTRL+V. If you repeatedly press CTRL+SHIFT+V, you cycle through the entries in the Clipboard Ring, selecting the item you want to paste.
This also works in Visual Studio 2015+
List all columns in a table
To quickly list all the columns in a table as a comma separated list, simply drag the ‘Columns’ folder in Object Explorer and drop it onto a query window. This creates a single line of comma separated column names; if you want to format as one column per line, you can use a search and replace utilising a newline with the regex search option turned on.
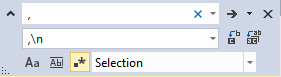
Highlight the comma separated list of columns you just created, type CTRL+H, turn on regular expression searching, enter a comma followed by a space , as the search text, and replace with a comma followed by a newline ,\n
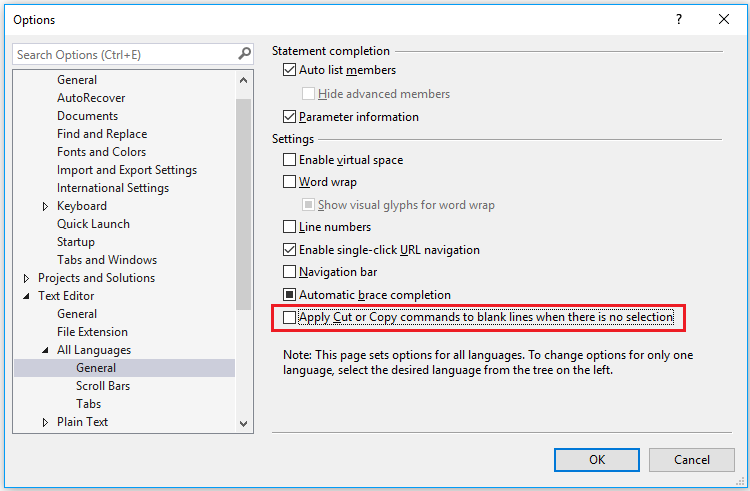
Disable Copy of Empty Text
Ever had this happen to you? You select a block of text to copy, move to the place you want to paste it, and then accidentally hit CTRL+C again instead of CTRL+V. Your block of copied text has been replaced by an empty block!
You can disable this behaviour (I have no idea why disabled is not the default): go to Tools -> Options -> Text Editor -> All Languages -> General -> ‘Apply Cut or Copy Commands to blank lines when there is no selection’ and uncheck the checkbox.
Set Tabs to Insert 4 Spaces
Avoid indentation inconsistencies when opening TSQL files in different editors: go to Tools -> Options -> Text Editor -> Transact-SQL -> Tabs -> Insert Spaces and click the radio button. Set Tab and indent size to 4.
Use GO X to Execute a Batch or Statement Multiple Times
The ‘GO’ command is not a Transact SQL statement but marks the end of a batch of statements to be sent to SQL Server for processing. By specifying a number after ‘GO’ the batch will be run the specified number of times. You can use this to repeat statements for creating test data. This can be a simpler alternative to writing a cursor or while loop.
create table MyTestTable
(
Id int not null identity(1,1) primary key,
CreatedDate datetime2
)
GO
This will run the insert statement 100 times:
insert into MyTestTable(CreatedDate)select GetDate()
GO 100
Templates and Code Snippets
Many users are not aware of SSMS’s Template Browser. These templates contain placeholders/parameters that help you to create database objects such as tables, indexes, views, functions, stored procedures etc.
By default when you open SSMS, the Template Explorer isn’t visible. Press Ctrl+Alt+T or use the View -> Template Explorer menu to open it. One of my favourite templates is the database mail configuration:
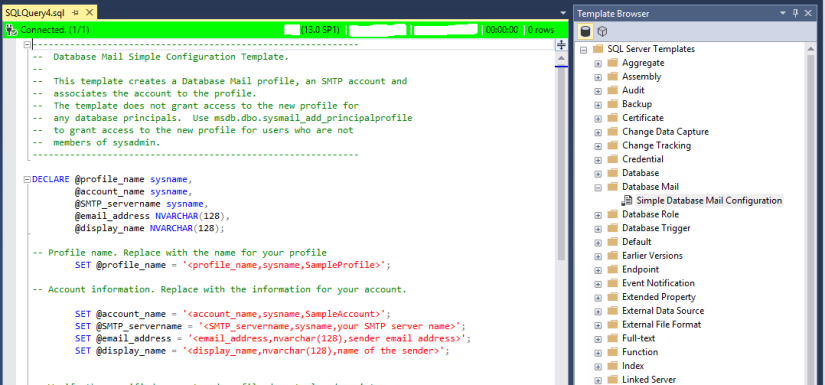
Template Explorer provides a view of a folder structure inside the SSMS installation, which is located at C:\Program Files (x86)\Microsoft SQL Server\XXX\Tools\Binn\ManagementStudio\SqlWorkbenchProjectItems\Sql
Templates contain parameter place holders: press Ctrl + Shift + M to open a dialog box that substitutes values for the template place holders:
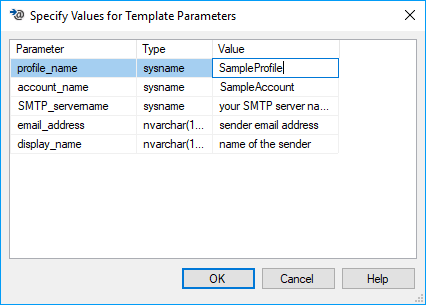
You can also add your own templates. Right-click on the SQL Server Templates node of the Explorer and choose New -> Folder and set the folder name. Then right-click on the folder and choose New -> Template. Add your code, with any parameters defined as:
< ParameterName, Datatype, DefaultValue >
Click Ctrl + Shift + M to check the parameter code blocks are well formed.
Code snippets are similar but simpler without parameters. Type CTRL + K + X to insert a code snippet.
Registered Servers
Most users have a number of servers they frequently connect to. The Registered Servers feature allows you to save the connection information of these frequently accessed servers.
You can create your own server groups, perhaps grouped by environment or by project.
Navigate to View -> Registered Servers. Then right-click on the ‘Local Server Groups’ and click on ‘New Server Registration’, and enter your connection details.
There is also a feature that allows windows only authentication to be used against a central server management server
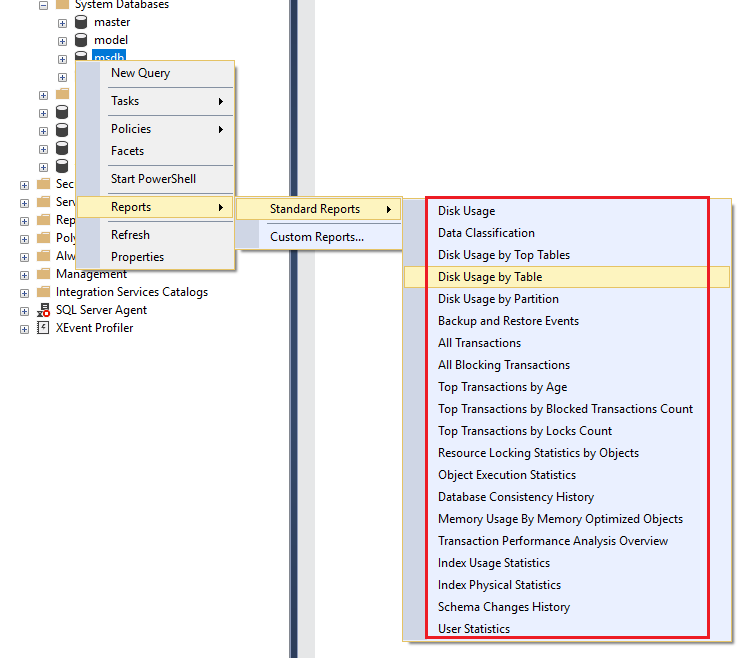
Built in Performance Reports in SSMS
SSMS provides a number of built in standard reports. To access the database level reports, right click on a Database –> Reports –> Standard Reports –> Select a Report:
Useful SSMS Keyboard Shortcuts
| Shortcut |
Action |
| CTRL+N |
Open new query with current database connection |
| CTRL+O |
Open a file in a new tab with current database connection |
| CTRL+R |
Toggle between displaying and hiding Results Pane |
| CTRL+M |
Include actual query execution plan |
| CTRL+L |
Display estimated query execution plan |
| CTRL+TAB |
Cycle through query windows |
| F4 |
Display the Properties Window |
| CTRL + ] |
Navigate to the matching parenthesis |
| CTRL+ALT+T |
Open Template Explorer |
| CTRL+SHIFT+M |
Specify values for Template parameters |
| CTRL+K+X |
Insert SQL code snippets |
| CTRL+SHIFT+U |
Change text to upper case |
| CTRL+SHIFT+L |
Change text to lower case |
| CTRL+K+C / CTRL+K+U |
Comment / Uncomment selected text |
| CTRL+F / CTRL+H |
Find / Replace |
Splitting the Query Window to work on large queries
The query window can be split into two panes so that you can view two parts of the same query simultaneously. To split the window, simply drag the splitter bar at the top right hand side of the query window downwards. Both parts of the split window can be scrolled independently. This is useful if you have a large query and want to compare different parts of the same query.
Vertical Block Select Mode
This is a feature I use often. You can use it to select multiple lines or a block of text over multiple lines, you can type text and it will be entered across all the selected rows, or you can paste blocks of text. To use it, hold down the ALT key, then left click on your mouse to drag the cursor over the text you want to select and type/paste the text you want to insert into multiple lines.
Keyboard Shortcut – ALT + SHIFT + Arrow Keys
Mouse – ALT + Left-Click + Drag
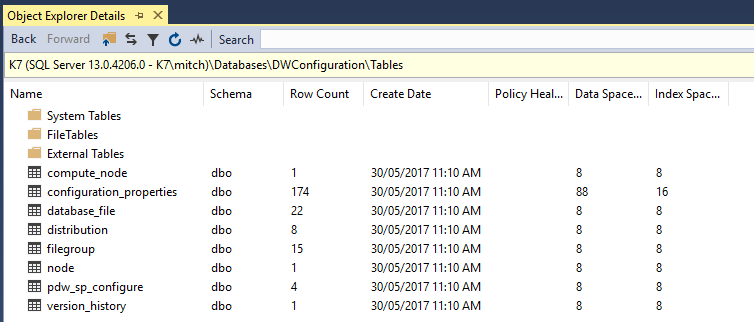
Object Explorer details
The Object Explorer Details window is a feature which very few developers use (including me, as I always forget it’s there!). It lists all the objects in a server and additional information like Row Count, Data Space Used, Index Space Used etc. It’s a quick way to see table row counts for all tables in a database.
The Object Explorer Details window is not visible by default. Click F7 or navigate to View -> Object Explorer Details to open it. To add columns, right click on the column header row and select those columns you want to see.
Display Query Results in a Separate Tab
If you want to focus on the results after you run a query, and would like to give it as much screen real estate as possible, go to Tools -> Options -> Query Results -> SQL Server -> Results To Grid and enable the option “Display Results in a separate tab”.

